From 5.6% to 62.3% Accuracy: Building a Self-Hosted Insurance Card OCR Service
Insurance card data entry is one of the most tedious bottlenecks in patient onboarding. Commercial OCR services charge per page and require sending patient data to third-party servers. I wanted to see
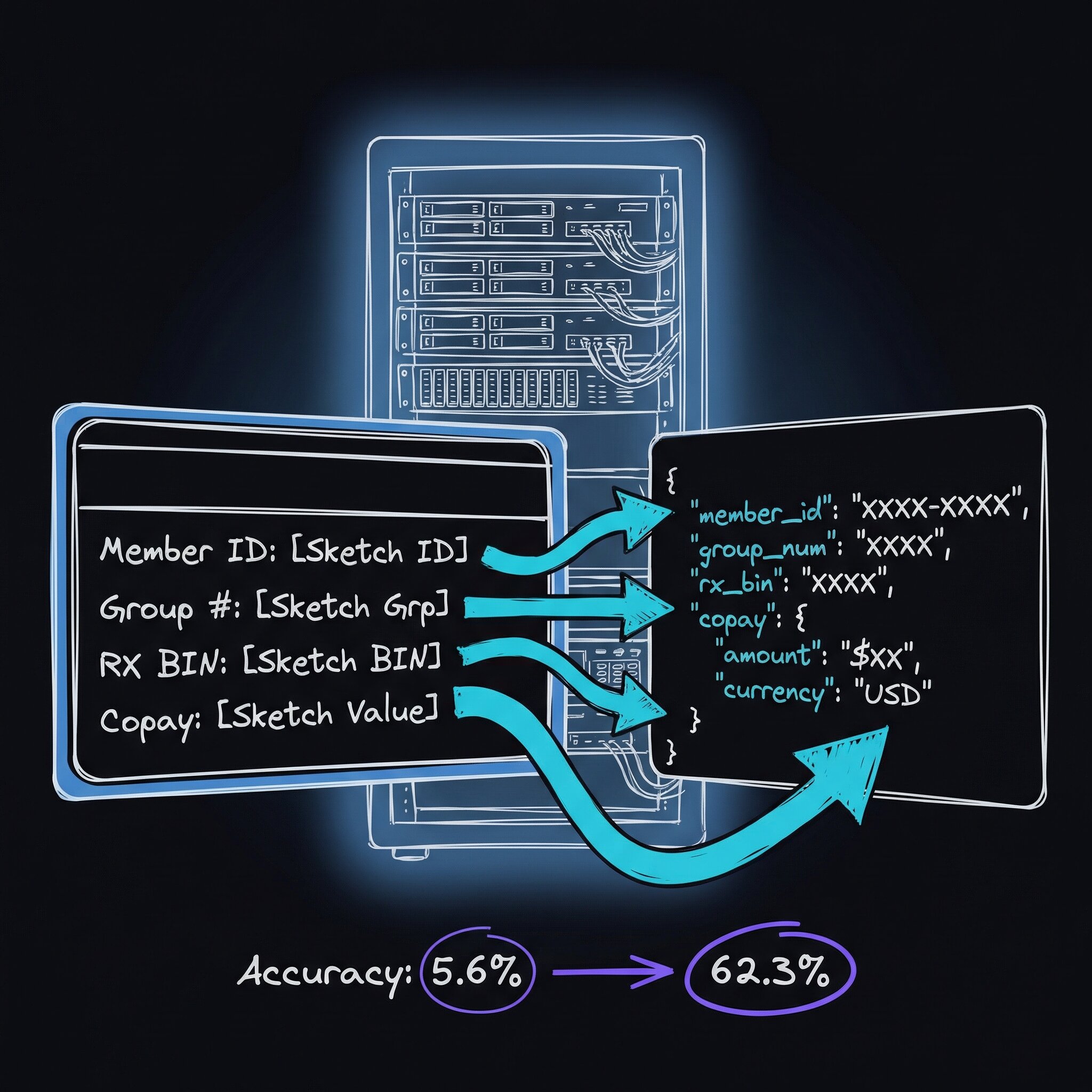
Insurance card data entry is one of the most tedious bottlenecks in patient onboarding. Commercial OCR services charge per page and require sending patient data to third-party servers. I wanted to see how far I could push a fully self-hosted alternative — one that keeps patient data on-premise and costs nothing per inference.
The Problem
Every patient who walks into an urgent care clinic hands over an insurance card. That card contains a dozen fields — member ID, group number, copays, RX BIN, payer ID — that someone has to manually key into the system. It’s slow, error-prone, and scales terribly across multiple clinic locations.
Commercial OCR APIs solve this, but they come with two costs: dollars per page (typically $0.10–$0.50 per inference) and the requirement to send patient insurance data to external servers. For a healthcare operation processing thousands of cards monthly, both costs add up.
The question: could a local vision model running on a single GPU handle insurance card extraction well enough to be useful?
The Stack
I built CardOCR as a lightweight FastAPI service running on a local GPU server:
- Hardware: Intel i9-10900K, 62GB RAM, NVIDIA RTX 3090 (24GB VRAM)
- Framework: FastAPI (Python)
- Vision Model: minicpm-v:8b via Ollama
- Process Manager: systemd
The service exposes a simple REST endpoint: POST an image, get back structured JSON with extracted fields. The entire deployment fits in a handful of files:
cardocr/
app/
main.py # FastAPI app, REST endpoints
extractor.py # Ollama vision extraction + image preprocessing
mindee_compat.py # Response format wrapper
config.py # Configuration (model, URLs, timeouts)
cardocr.service # systemd unit fileThe Optimization Journey
Getting from “it runs” to “it’s useful” took five distinct phases. Each one taught me something about working with vision models.
Phase 1: Naive Approach — 5.6% Accuracy
My first attempt used gemma3:12b with a null-template prompt — essentially asking the model to fill in a JSON template with null values replaced by extracted data.
Root cause: Vision models treat null templates as expected output. The model would happily return the template unchanged, treating the nulls as the “correct” answer.
Phase 2: Model Selection — 39.2% Accuracy
Switching to minicpm-v:8b and using Ollama’s /api/chat endpoint (rather than /api/generate) made a massive difference. The chat-based interface gives the model conversational context about the task.
Lesson: Model selection matters more than prompt engineering. Gemma3 fundamentally couldn’t read insurance cards; MiniCPM-V excelled at it with the same prompts.
Phase 3: Descriptive Prompts — 60.7% Accuracy
Instead of asking the model to fill a template, I described each field with guidance about where to find it on a typical card and what format to expect. For example, telling the model that RX BIN is usually a 6-digit number found near pharmacy benefit information.
Phase 4: Image Preprocessing — 73.8% Accuracy
This was the highest-ROI optimization of the entire project. Two simple transforms:
- Upscaling: Ensuring the shortest dimension is at least 1200px
- Contrast enhancement: Applying a 1.15x contrast multiplier
The upscaling alone added 13 percentage points. Insurance cards are small, and phone photos of them are often blurry — giving the model more pixels to work with made a dramatic difference.
Why 1.15x contrast? I tested multipliers from 1.0 to 1.5. Too little contrast and faded text stays unreadable. Too much and colors bleed together, making colored text on colored backgrounds worse. 1.15x hit the sweet spot.
Phase 5: Benchmarking on Diverse Data — 62.3% Accuracy
Here’s where the story gets honest. My initial test set of 10 carefully selected images showed 80.2% accuracy. When I expanded to a diverse 30-image benchmark with varied card designs, lighting conditions, and image quality, accuracy dropped to 62.3%.
This is the most important lesson of the project: always benchmark on diverse, representative data. A narrow test set gives false confidence.
Field-Level Results
Not all fields are created equal. Here’s the breakdown across 30 test images:
| Field | Accuracy |
|---|---|
| Company Name | 86.5% |
| Member Name | 79.6% |
| RX BIN | 79.4% |
| Member ID | 75.9% |
| Group Number | 65.9% |
| RX PCN | 64.3% |
| Plan Name | 56.2% |
| Copays | 47.5% |
| RX Group | 43.8% |
| Payer ID | 40.0% |
| Enrollment Date | 33.3% |
| Overall Average | 62.3% |
The pattern makes sense. Large, prominent text (company name, member name) extracts well. Small, variable-format fields (enrollment dates, payer IDs) are much harder. Copays are particularly tricky because they appear in different formats across insurers — sometimes as a table, sometimes inline, sometimes with dollar signs and sometimes without.
Key Takeaways
1. Model selection beats prompt engineering. Gemma3:12b scored 5.6%. MiniCPM-V:8b scored 39.2% with the same prompts. When a model can’t do the task, no amount of prompt craft will fix it.
2. Image preprocessing is the cheapest accuracy boost. A few lines of PIL code for upscaling and contrast enhancement delivered a 13-point improvement. Always pre-process your inputs before blaming the model.
3. Never prompt with null templates. Vision models interpret null/empty values as the desired output. Use descriptive prompts that explain what you’re looking for instead.
4. Use the chat endpoint, not generate. Ollama’s /api/chat gives the model conversational context. For structured extraction tasks, this consistently outperforms /api/generate.
5. Benchmark honestly. Ten cherry-picked images said 80%. Thirty diverse images said 62%. The latter is the number that matters.
6. The self-hosted tradeoff is real. 62% accuracy vs. 95%+ from commercial services. Zero marginal cost vs. $0.10–$0.50 per page. Whether this tradeoff works depends on your use case — pre-filling fields for human review is viable, fully automated extraction is not.
When Does Self-Hosted OCR Make Sense?
This project isn’t a commercial OCR replacement. But it is useful as:
- A pre-fill assistant: Extract what you can, let staff correct the rest. Even 62% accuracy reduces keystrokes significantly.
- A triage tool: Identify the insurance company and plan type to route the card to the right workflow.
- A privacy-first option: When sending patient data to external APIs isn’t acceptable, some accuracy is better than none.
- A starting point: The architecture supports swapping in better models as they become available. Vision models are improving rapidly.
What’s Next
Several optimizations remain untested:
- Multi-pass extraction: Run different prompts targeting different field groups, then merge results
- Card-type detection: Identify the insurer first, then use insurer-specific field hints
- Fine-tuned models: Train on a labeled dataset of insurance cards (the biggest potential accuracy gain)
- Confidence calibration: Let the model express uncertainty so low-confidence extractions get flagged for human review
- Back-of-card extraction: Many fields (RX info, appeals numbers) live on the back
The self-hosted vision model space is moving fast. Models that couldn’t read insurance cards a year ago now extract most fields correctly. The gap between local and commercial will keep closing — and when it does, having the infrastructure already in place will be a significant advantage.