PAI: The Operating System I Built Around My AI Assistant
The first real sign I had a system rather than a workflow was when I noticed the assistant failing gracefully.
The first real sign I had a system rather than a workflow was when I noticed the assistant failing gracefully.
I’d asked it to do something complex. In an earlier era, that would have produced a wall of freeform text or a misguided half-answer. Instead, it loaded a planning document, ran a structured multi-step analysis, reported the result in a consistent format, and committed the context to a memory file for the next session. Then it waited.
That sequence — load, plan, execute, remember, report — wasn’t something I’d asked for in that session. I’d built it into the infrastructure.
What “Infrastructure” Means Here
I’ve written before about project-level skills — DevFlow, BugBot, and similar workflows tied to specific repositories. Those are powerful. But there’s a layer below them: global configuration that applies everywhere, across every project, on every machine.
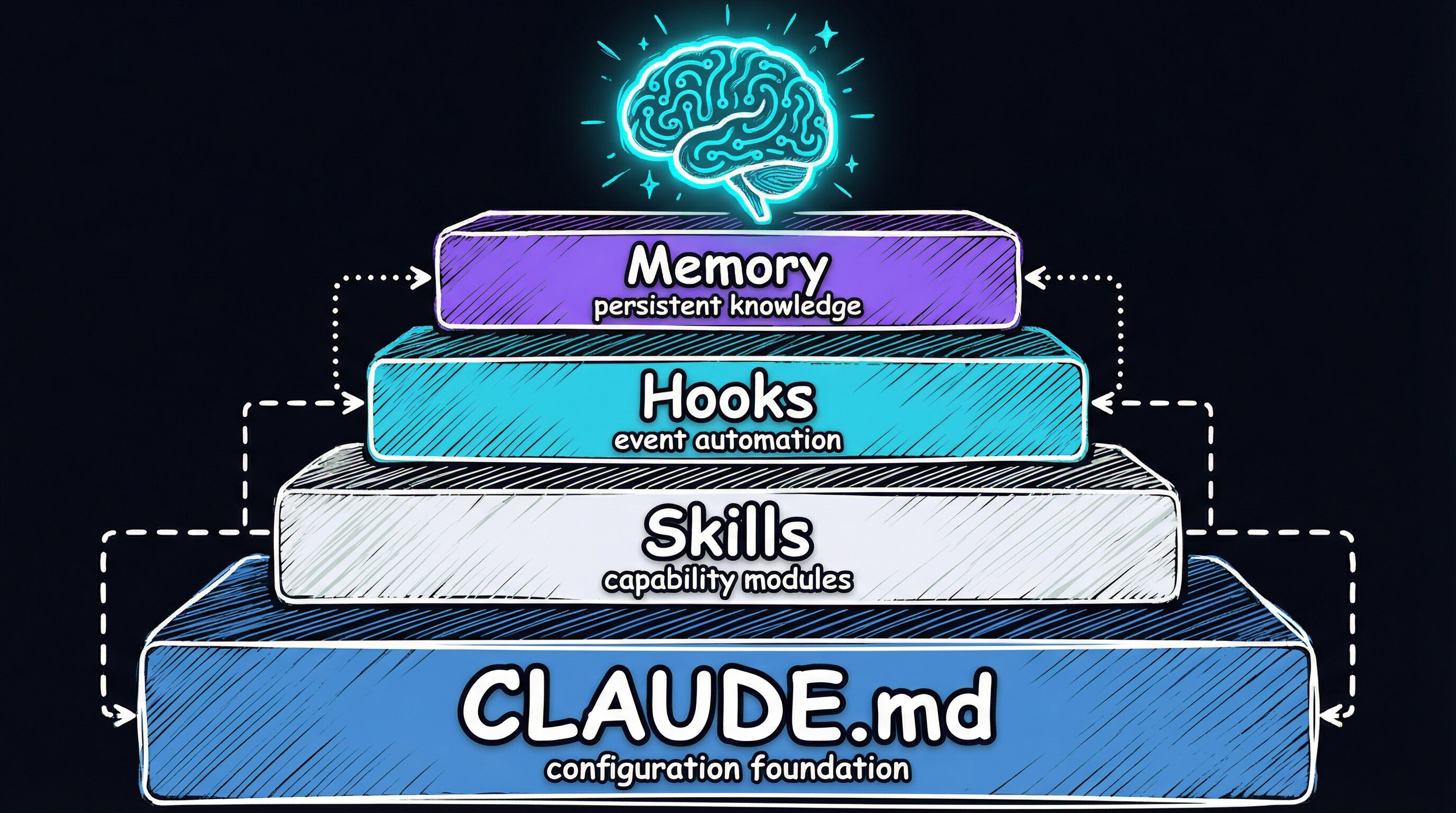
That global layer is what I call PAI — Personal AI Infrastructure. It has five components:
| Component | What It Does |
|---|---|
| CLAUDE.md | Global instructions: operating modes, stack preferences, machine topology |
| Skills | Reusable workflows invoked by slash command across any project |
| Hooks | Event-driven automation that fires on tool use and session events |
| Memory | Persistent markdown files that survive across sessions |
| claude-config repo | Git-versioned source of truth, CI-deployed to all machines |
The repo and deployment approach is covered in detail in the companion post. This post focuses on what’s inside.
Operating Modes: Structured Responses by Default
The single highest-leverage piece is mode enforcement. Every response begins by classifying the request:
- MINIMAL — acknowledgments, short answers
- NATIVE — quick single-step tasks
- ALGORITHM — multi-step, complex, or difficult work
NATIVE mode uses a fixed output format: task, work, change, verify, summary. ALGORITHM mode loads a formal planning document and follows it exactly — structured planning phases, parallel agent spawning, explicit completion checks. Freeform prose responses are not allowed in either mode.
The effect is counterintuitive. Rigid format sounds like it would slow things down. It doesn’t. When the output structure is predetermined, zero cycles get spent deciding how to respond — just classify and execute. Sessions are faster and more consistent.
Skills: Global Workflows That Travel With You
Previous posts covered project-level skills. User-level skills live in ~/.claude/skills/ (deployed via claude-config) and are available in every project, on every machine.
My 43 user-level skills cover the full development lifecycle:
| Category | Skills |
|---|---|
| Dev workflow | DevFlow (pipeline enforcer), BugBot (adversarial review), CodeReview |
| Content | BlogWriter, Media, Art (Excalidraw diagrams), VideoToSpec |
| Research | Research (multi-agent, 4 modes), Investigation, ContentAnalysis |
| Infrastructure | StandupService, DeployOneContext, ChromeMCP, AgentBrowser |
| AI development | Agents, Thinking, Prompting, gcc (memory commits) |
The key distinction from project skills: these are identity skills — they define how the assistant operates everywhere, not just in one project. DevFlow at the user level enforces the same git pipeline whether I’m in a React app or a Python service.
Hooks: Automation That Fires Automatically
Claude Code supports hooks — scripts that fire on specific events during a session. I use three categories:
Security validation — a pre-tool hook intercepts every bash command before it executes and blocks patterns that look destructive (mass deletions, force pushes, skipping verification hooks). It’s a last-resort guardrail, implemented as a Bun TypeScript script that runs in under 50ms.
Audio notifications — a voice hook calls a local notification server to announce which mode the assistant is entering. I can hear when it kicks into a complex workflow without watching the screen.
Memory commits — a post-operation hook writes significant context into structured markdown using the GCC memory system, so the next session can orient itself using previous work.
Memory: Persistence Across Sessions
Claude Code doesn’t remember previous sessions by default. The GCC system (described in detail here) solves this by committing structured context to markdown files in the repo. The memory files survive session boundaries and are loaded at startup.
Two kinds of memory:
~/.claude/projects/memory/MEMORY.md # Always loaded — cross-session patterns
claude-config/MEMORY/ # Work logs — recent decisions, architectural contextThe key insight from the GCC paper is that agents need semantic memory organized by topic, not chronological logs. A file titled debugging.md is more useful than a timestamp-sorted journal.
What I Learned
The global layer enables the project layer. Project-level skills can rely on global infrastructure. When a BugBot loop needs to spawn a parallel review agent, it doesn’t define that agent inline — the user-level Agents skill handles it. Each layer makes the others more powerful.
Modes prevent drift. Without a strict response format, the assistant makes different structural choices in different sessions. Sometimes useful, usually inconsistent. Locking the format means every session is predictable.
Infrastructure is worth the up-front cost. Setting up the claude-config repo, writing the deploy script, configuring CI runners — that took a weekend. Every session since has benefited from it. The ROI compounds.
Tools used: Claude Code by Anthropic, Bun runtime for hooks, GitHub Actions for CI/CD. Source: RooseveltAdvisors/claude-agent-stack.