Implementing the GCC Paper: Giving AI Agents Persistent, Structured Memory
I run AI coding agents across multiple machines, multiple sessions, sometimes for days at a time. The biggest frustration isn't capability — it's amnesia. Every new session starts from zero. The agent
I run AI coding agents across multiple machines, multiple sessions, sometimes for days at a time. The biggest frustration isn’t capability — it’s amnesia. Every new session starts from zero. The agent has no memory of yesterday’s architectural decisions, the bug it spent an hour debugging, or the branch it was exploring before the context window filled up. I’d re-explain the same project context over and over, watching tokens burn.
Then I read GCC: Git-Context-Controller by Junde Wu at Oxford, and it clicked. The paper treats agent memory not as a flat text file, but as a version-controlled codebase — with commits, branches, merges, and multi-resolution retrieval. I spent a week implementing it from scratch. Here’s what I learned.
The Paper’s Core Insight
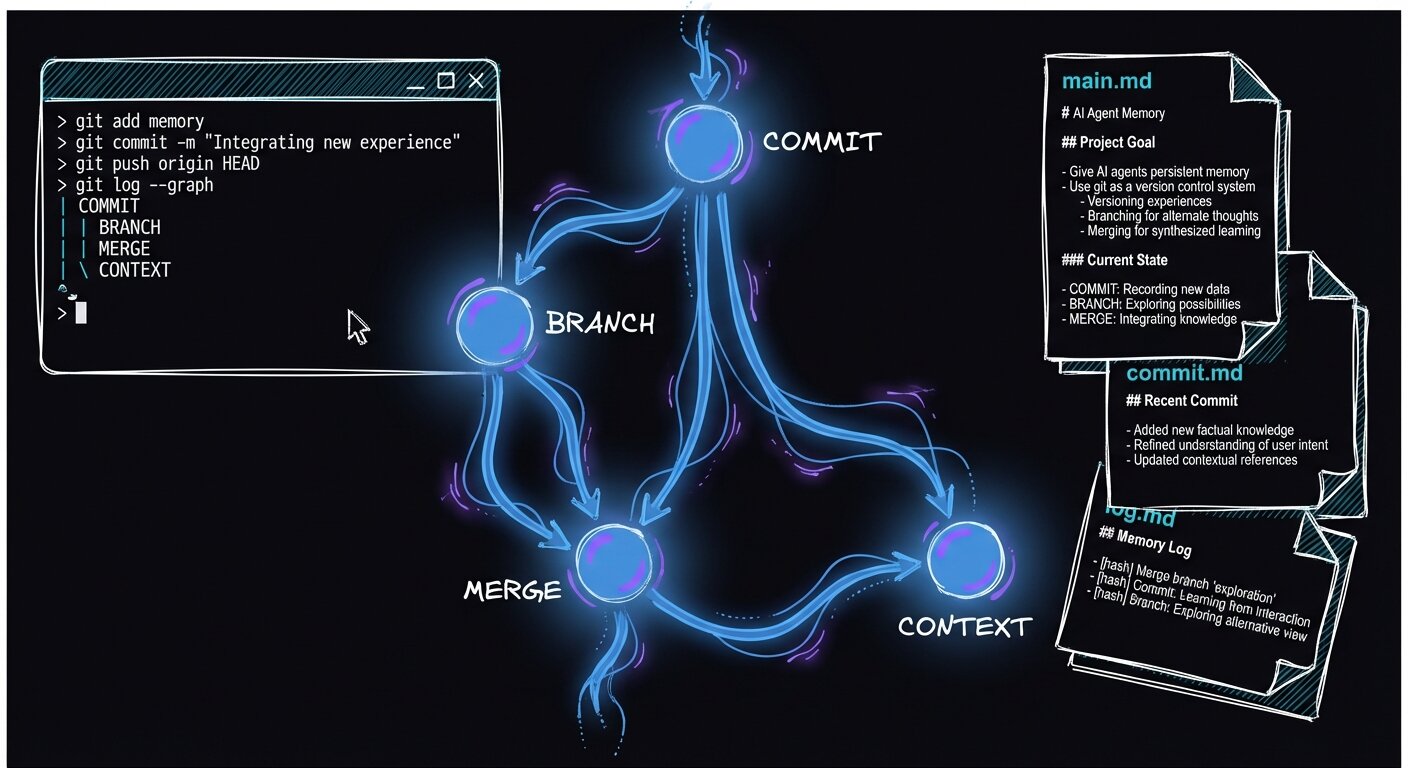
The GCC paper (arXiv 2508.00031) introduces four operations that agents can call during reasoning — modeled directly after Git:
| Command | When to Call | What It Does |
|---|---|---|
COMMIT | After a coherent milestone | Checkpoints progress with a three-block narrative summary |
BRANCH | Before exploring an alternative | Creates an isolated workspace for experiments |
MERGE | When an experiment succeeds | Synthesizes branch results back into the main trajectory |
CONTEXT | To orient or resume work | Retrieves memory at multiple resolutions |
The key architectural idea: agent memory lives in a .GCC/ directory with main.md (global roadmap), and per-branch commit.md (milestone summaries), log.md (fine-grained OTA traces), and metadata.yaml (file structure, dependencies, configs). Agents equipped with GCC achieved 48% resolution on SWE-Bench-Lite — SOTA at the time, outperforming 26 competitive systems.
What I Built: gcc-memory
gcc-memory is my open-source implementation. It’s ~2,600 lines of Python, structured in four layers:
src/gcc_memory/
├── store.py # 757 LOC — core storage engine
├── cli.py # 447 LOC — Typer CLI (commit, branch, merge, context)
├── utils.py # Atomic writes, file locks, timestamps
├── server.py # HTTP + WebSocket for real-time streaming
└── adapters.py # Codex/Claude/OpenCode transcript parsers
integrations/claude/
├── gcc_memory_observe.py # UserPromptSubmit hook → observations
├── gcc_memory_stop.py # Stop hook → thoughts
├── gcc_memory_sync.py # PostToolUse hook → actions
└── hook_common.py # Shared: debounce, dynamic import, trimming
scripts/
├── backfill_history.py # Mine 800+ session transcripts into events
└── run_backfill.sh # uv-backed runnerThe Three-Block Commit
The paper’s most distinctive feature is the three-block commit format. Each commit captures:
- Branch Purpose — why this branch exists (anchors intent)
- Previous Progress Summary — compressed history (chains prior summaries)
- This Commit’s Contribution — what changed in this milestone
### Commit: Implement JWT auth (2026-02-18T10:30:00+00:00 | main)
**Branch Purpose:** Full-stack authentication system
**Previous Progress Summary:** Set up Express server with route structure.
Added PostgreSQL connection pool with migration system.
**This Commit's Contribution:**
Replaced session cookies with JWT tokens. Simplifies the API gateway
and enables stateless horizontal scaling. Validated with integration
tests covering token refresh, expiry, and revocation.The trick is _synthesize_progress() — it chains previous summaries with a 1,500-character cap, so N commits compress to a fixed-size window. After 50 commits, you still get a coherent summary that fits in a few hundred tokens.
Three Hooks, Three OTA Channels
The paper specifies Observation-Thought-Action (OTA) traces. I capture all three via Claude Code hooks:
| Hook | Event Type | Channel | What It Captures |
|---|---|---|---|
UserPromptSubmit | Observation | claude-hook | User’s request (the “what”) |
Stop | Thought | claude-hook | Agent’s reasoning (the “why”) |
PostToolUse | Action | claude-hook | Tool execution (the “how”) |
The PostToolUse hook is the richest — it builds enriched summaries instead of just logging tool names:
# Instead of: "bash"
# We get: "migrate database schema (exit 0)"
def _build_enriched_summary(tool_name, payload):
if tool_name == "bash":
desc = tool_input.get("description", "")
exit_code = result_obj.get("exit_code", "")
return f"{desc} (exit {exit_code})" if desc else cmd[:120]Two critical filters keep logs clean: debouncing (3-second window prevents duplicate events from rapid-fire hooks) and noise filtering (skip terse responses under 60 characters like “Done.” or “OK.”). This cuts log noise by ~70% while losing almost nothing of value.
Auto-Commit as Safety Net
Every 300 seconds of continuous tool activity, the PostToolUse hook triggers an auto-commit. But the real value comes from agent-driven narrative commits — the skill explicitly teaches: “Auto-commit is a fallback; your narrative commits and curated summaries are what make this memory useful to future sessions.”
The Hardest Part: Backfill
The biggest engineering challenge wasn’t the storage engine — it was making the memory system useful for projects that already had months of history. The ~/.codex/history.jsonl file only contains user prompts. No agent reasoning, no tool calls, no files changed. Memory built from prompts alone was nearly useless.
The breakthrough: Claude stores full session transcripts at ~/.claude/projects/{project}/*.jsonl. Each transcript contains the complete conversation — user messages, assistant reasoning blocks, and tool calls with inputs and outputs. I wrote a parser that mines these:
def _parse_transcript(path: Path) -> dict | None:
for record in records:
if record["type"] == "user":
user_texts.append(extract_text(record))
elif record["type"] == "assistant":
for block in record["message"]["content"]:
if block["type"] == "text":
reasoning_parts.append(block["text"])
elif block["type"] == "tool_use":
tool_calls.append(summarize(block))
if block["name"] in ("Edit", "Write"):
files_changed.add(block["input"]["file_path"])For the ARCS Health Portal — a project with 36 days of development history — this mined 655 Claude sessions and 733 Codex prompts, producing commits like:
2026-01-19 (37 sessions)
[16:37] Implement batch lab upload feature
Reasoning: Let me start by reading the specification
Files changed: lab_upload.py, lab_upload_store.py, name_extractor.py
[18:24] Let user mark invalid form history and lab results
Reasoning: Let me look at the data stores and template
Files changed: ehr.py, filled_form_store.py, patient_detail.htmlNight and day compared to the prompts-only version.
Closing the Paper Gap
After the initial implementation, I ran a systematic comparison against the paper. Here’s where things stood and what I fixed:
| Paper Requirement | Initial State | Fix |
|---|---|---|
| Git commit on COMMIT/MERGE | Not implemented | Added --git flag |
| MERGE calls CONTEXT on target first | Missing | Added context_branch() call before merge |
| BRANCH initializes commit.md | Empty file | Writes initial entry with Branch Purpose |
| main.md has milestones + to-do list | Only Purpose/Decisions/Questions | Added Milestones and To-Do sections |
| Per-file responsibilities in metadata | Path list only | Documented as optional (paper says “manually added”) |
The git integration was the most significant gap. The paper says COMMIT “finalizes the memory and code changes as a Git commit, using the agent-authored summary as the commit message.” Now gcc-memory commit --git does exactly that — staging all changes and creating a real git commit alongside the GCC commit.
Lessons Learned
File-based storage scales surprisingly well. For a single workspace with 1-3 agents, Markdown + YAML with file locks is simple, auditable, and sufficient. Every event is visible in log.md. Every commit is human-readable in commit.md. No database migrations, no server dependency.
Structure events for the future, not just the present. Storing observation/thought/action on every event felt like over-engineering initially. But when I needed to build the backfill system, having a consistent OTA schema made it possible to reconstruct structured memories from raw transcripts.
Agent curation beats automation. The hardest lesson. My first approach was to auto-generate everything — summaries, highlights, main.md updates. The result was technically correct but useless. The breakthrough was treating agents as curators: the skill tells them when and how to update main.md, but they write the content. The difference in quality is dramatic.
Mine transcripts, not just prompts. This was the pivotal discovery. history.jsonl (user prompts only) produces memory that’s one-sided and shallow. Session transcripts contain the full reasoning chain — what the agent considered, what it tried, what files it changed. That’s where the real institutional knowledge lives.
Try It
gcc-memory is open source at github.com/RooseveltAdvisors/gcc-memory
git clone https://github.com/RooseveltAdvisors/gcc-memory
cd gcc-memory && bash install.shAll credit for the GCC framework goes to Junde Wu’s paper. I just built an implementation and learned a lot along the way.