Git Worktrees Ate My Edits — Why We Switched to Dedicated Machines for Agent Isolation
I was in the middle of a refactor — removing dead code from a shared SDK module — when my edits vanished. No error. No warning. Just gone.
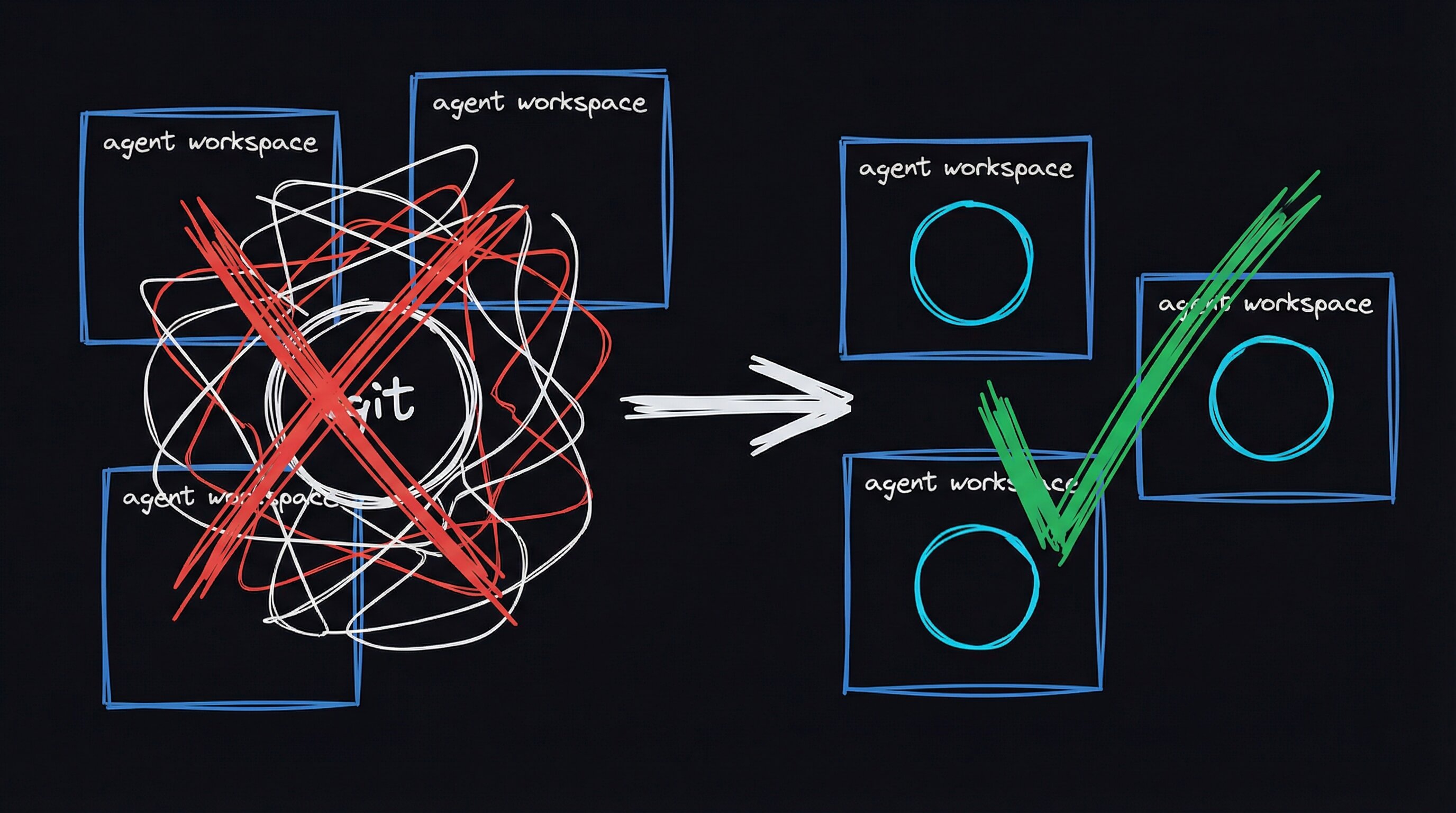
I was in the middle of a refactor — removing dead code from a shared SDK module — when my edits vanished. No error. No warning. Just gone.
I’d been running a fleet of AI agents, each in its own git worktree, while I edited files on the main checkout. One git checkout -- . to clean up an agent’s stray files, and my staged changes disappeared with them. The worktree isolation model had silently failed.
The Setup That Seemed Right
Git worktrees are an elegant idea for parallel agent work. Each agent gets its own working directory, but they share the same .git directory — same object store, same refs. Claude Code’s isolation: "worktree" flag creates these automatically.
/opt/project/ # Main checkout (orchestrator)
/opt/project/.claude/worktrees/
├── agent-a1b2c/ # Agent 1's worktree
├── agent-d3e4f/ # Agent 2's worktree
└── agent-g5h6i/ # Agent 3's worktreeLightweight, fast, no network overhead. Each agent can work on a different branch without cloning the entire repo. What’s not to love?
What Actually Happened
The orchestrator session — the one coordinating all the agents — was editing files directly on the main checkout. Meanwhile, three agents were running in worktrees doing their own feature work.
Here’s where it broke down:
- I edited
agent_sdk.pyon the main checkout, staged it - A worktree agent hit an issue and fell back to operating on the main checkout directly
- That agent modified files I wasn’t tracking —
daemon.py, some test files - I ran
git checkout -- .to clean up the agent’s mess - That command restored ALL files to HEAD — including my staged
agent_sdk.pychanges
The fix was copying the repo to /tmp/ — a completely independent clone with its own .git directory. Made changes, committed, pushed. No interference possible.
Why Worktrees Can’t Be Fully Trusted
The shared .git directory is the fundamental problem.
| Shared State | Risk |
|---|---|
| Object store | Lock contention during concurrent writes |
| Refs / branches | Agents can see and switch to each other’s branches |
| Index / staging area | Main checkout staging is visible to worktree operations |
| HEAD pointer | git checkout on main affects what agents see |
| Lock files | Concurrent git operations can deadlock |
When an agent encounters a worktree error — permissions, lock contention, disk issues — the natural fallback is operating on the original checkout. That fallback is silent and destructive.
Mitigations I Considered
I went through the standard hardening approaches:
| Approach | Why It Fails |
|---|---|
| ”Just remember not to edit the main checkout” | Fragile under pressure — fails on attempt #100 |
| Lockfile guard script | Voluntary compliance, easy to bypass |
Filesystem permissions (chmod -R a-w) | Breaks git fetch/git pull |
| Orchestrator also uses a worktree | Still shares .git, still has edge cases |
| Bare repo with all worktrees | Adds complexity without eliminating shared state |
Every mitigation was trying to add discipline on top of a fundamentally shared resource. The answer was removing the shared resource entirely.
The Answer: Dedicated Machines
We already had a fleet of agent machines on the same LAN — small form-factor PCs running Ubuntu, each with its own disk, its own git clone, its own everything. Dispatching work to them instead of worktrees gives you:
- Total filesystem isolation — separate
.git, separate object store, no shared state - Zero discipline required — there’s nothing to accidentally corrupt
- Clean failure modes — if an agent goes haywire, it trashes its own box
- No fallback path — an agent can’t “fall back” to editing the orchestrator’s files
The overhead? About 2-3 seconds per dispatch over SSH on a local network. A trivial cost for never losing edits again.
# Before: worktree (shared .git)
claude --worktree /opt/project "fix the auth module"
# After: dedicated machine (fully isolated)
ssh agent-box "cd ~/project && claude 'fix the auth module'"Stripe’s Validation
This isn’t just my experience. Stripe’s engineering blog documented the same journey — they moved away from git worktrees for their agent fleet for the same reasons. Shared git state creates subtle, hard-to-debug corruption. The failure mode is always silent data loss, the worst kind of bug.
Production Details
- Fleet: 15 dedicated agent machines, each with full repo clones
- Dispatch: Custom CLI tool routes work to available machines via SSH
- Sync: Agents push to the same remote origin — coordination happens through git branches, not shared filesystems
- Orchestrator: Development server stays clean — only used for human editing and dispatch coordination
- Overhead: 2-3 seconds SSH latency per dispatch, negligible for tasks that run minutes to hours
What I Learned
Structural isolation beats behavioral discipline. If the wrong action is possible, someone (or something) will eventually take it. Worktrees require you to remember rules. Dedicated machines make the wrong thing impossible.
The “elegant” solution isn’t always the right one. Worktrees are clever — shared object store, lightweight branching, no network overhead. But cleverness that creates subtle failure modes is worse than a blunt solution that just works.
Build for the failure mode, not the happy path. Worktrees work perfectly 99% of the time. But the 1% failure — silent data loss with no recovery — is catastrophic enough to justify the simpler, heavier approach.
Built with Claude Code by Anthropic. Inspired by Stripe’s blog post on agent infrastructure. Fleet management via custom dispatch tooling.