Version-Controlling Your AI's Brain
I had four machines. My AI assistant behaved differently on each one.
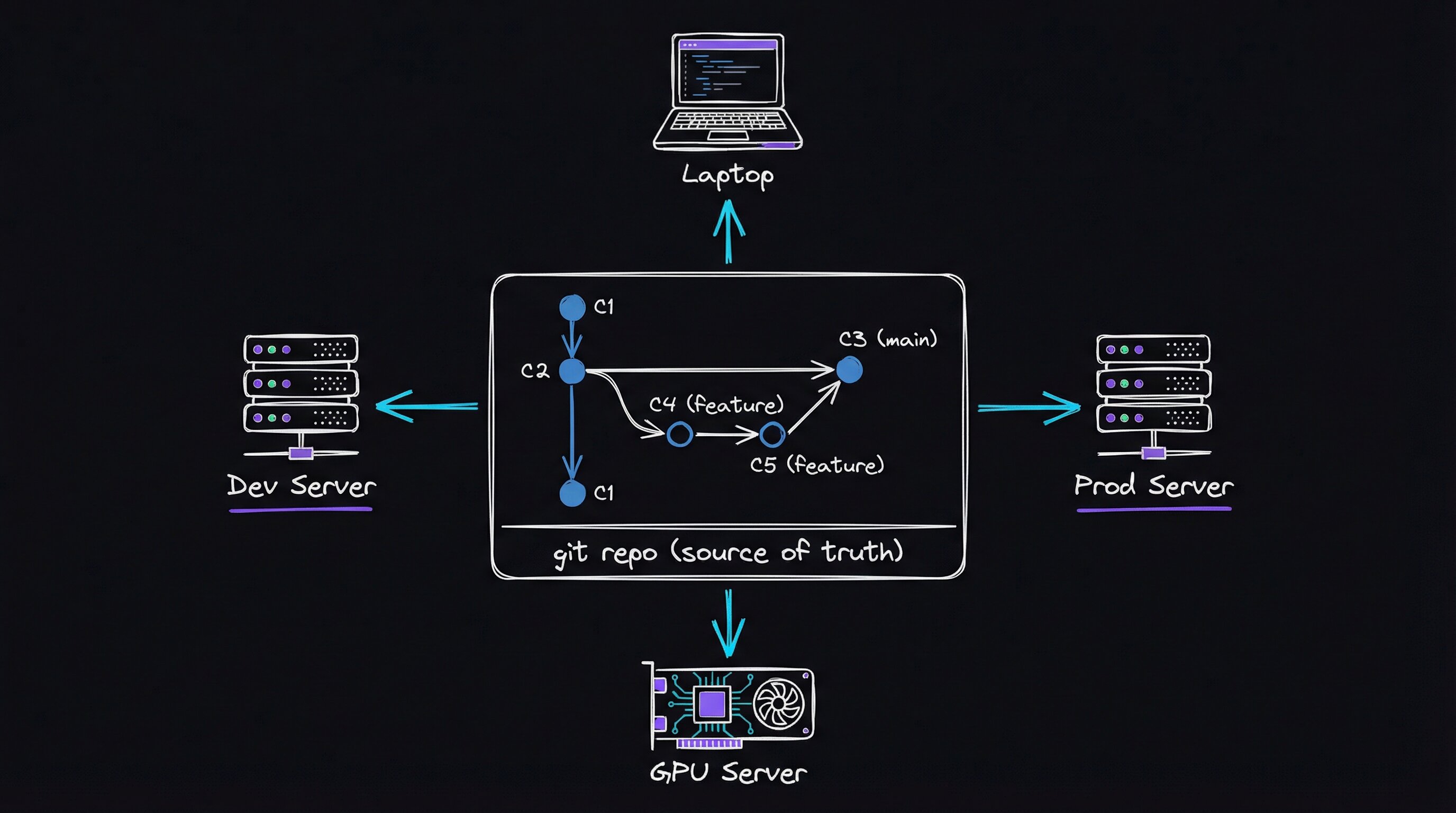
I had four machines. My AI assistant behaved differently on each one.
The dev server was running skills I’d updated three weeks ago and never pushed anywhere else. The production server had a custom hook I’d added in a late-night debugging session and completely forgotten about. The GPU workstation had a global config that was months behind. My laptop — the machine I actually developed on — had the latest everything. But “latest” only meant something on one machine.
I wasn’t managing my AI config. I was accumulating it.
The Problem with Editing Files Directly
Claude Code (Anthropic’s AI coding agent) stores all of its personalization in ~/.claude: a global instructions file, skills, hooks, subagent definitions, and slash commands. It’s a directory, not a service — so the default workflow is to edit it directly on whatever machine you’re on.
That worked fine for one machine. As soon as I had two machines, I had drift. After four, I had chaos. Every time I improved something — a new skill, a better hook, a clarified instruction — I had to manually propagate it. I usually didn’t.
Sound familiar? It’s the same problem as editing nginx config directly on production servers. The fix is the same too.
The Solution: Treat ~/.claude Like Infrastructure
I created a git repository — claude-config — that contains everything that should live in ~/.claude:
claude-config/
├── CLAUDE.md # Global instructions (modes, rules, machine topology)
├── deploy.sh # Sync to any/all machines
├── skills/ # ~43 skills: DevFlow, BugBot, BlogWriter, Research...
├── hooks/ # Event-driven automation
├── agents/ # Subagent definitions
└── commands/ # Slash commandsThe deploy.sh script uses rsync to push everything into ~/.claude on whatever target you specify:
./deploy.sh local # Apply to this machine's ~/.claude
./deploy.sh all # Push to all machines at onceRemote machines run self-hosted GitHub Actions runners. When I push to main, CI runs three checks (secret scanning, shell script linting, skill structure validation), then each remote machine’s runner deploys to its own ~/.claude. The whole process takes under a minute.
What Goes In, What Stays Out
Not everything belongs in the repo:
| Tracked in Repo | Stays Local |
|---|---|
CLAUDE.md (global instructions) | settings.json (API keys) |
| All skills and hooks | settings.local.json |
| Agents and commands | history.jsonl / session data |
| PAI user overrides | Cache, telemetry |
Secrets stay local. Everything that shapes the assistant’s behavior — instructions, workflows, automation — is version-controlled.
The Development Workflow
Updating a skill or changing an instruction is now a proper pull request:
git checkout -b fix/update-skill-angles
# ... edit skills/BugBot/Workflows/AdversarialReview.md ...
git add -A && git commit -m "fix: add data pipeline attack angle"
git push # CI runs checks, then deploys to all remote machines
./deploy.sh local # Apply to laptop (no persistent runner there)Before this repo existed, I was directly editing ~/.claude/skills/ on whichever machine I happened to be using. Now that directory is a deploy target — never edited directly. The source of truth is always the repo.
Results
- Four machines, one config. Any change I make is everywhere within two minutes of a push.
- Instant rollbacks. If a skill change breaks something,
git revertand push. Total downtime: one CI run. - Audit trail. Every change to how my assistant behaves is in the git log with a commit message explaining why.
- Review gate. PRs give me a checkpoint before config changes go live. CodeRabbit reviews every PR automatically.
What I Learned
Config drift is quiet. When your AI assistant behaves differently on different machines, you don’t usually notice immediately. You notice later, when you’re trying to reproduce a workflow or debug why something worked on one machine but not another.
The deploy target pattern generalizes. Don’t edit ~/.claude directly, ever — just like you don’t edit a config file directly on a production server. Have a source, have a deploy step, have a record.
Hooks and agents need version control too. It’s tempting to think only the “instructions” matter. But hooks (event-driven automation) and agent definitions shape behavior just as much as the instructions file. They all go in the repo.
Tools used: Claude Code by Anthropic, GitHub Actions for CI/CD, CodeRabbit for automated PR review. Source: RooseveltAdvisors/claude-agent-stack.