The 4-Line Architecture That Beat Complex AI Frameworks
Claude Code's entire architecture is fundamentally just one while loop. Not as a simplification—literally. While competitors build orchestration frameworks with task queues, agent hierarchies, and com
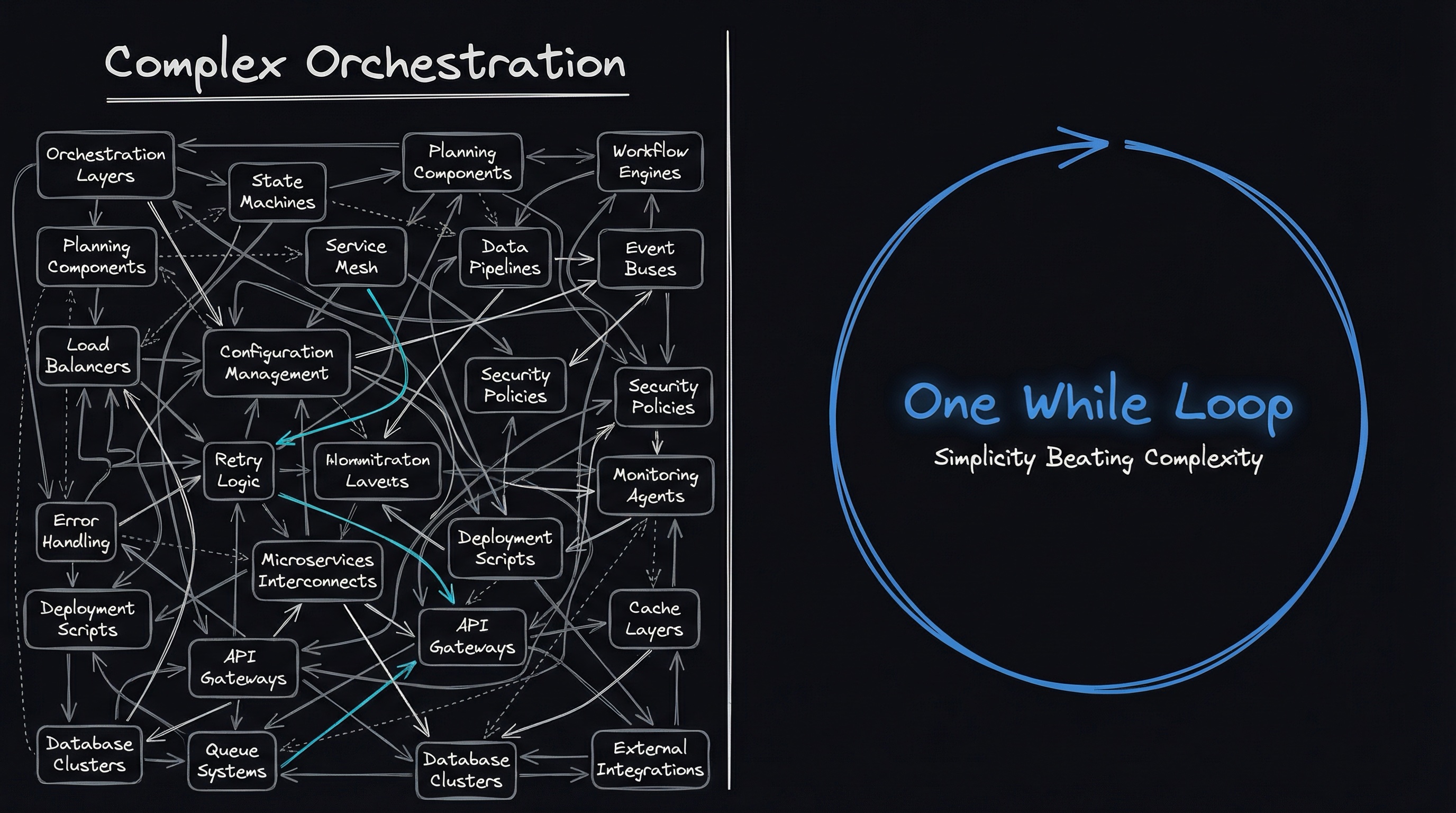
Claude Code’s entire architecture is fundamentally just one while loop. Not as a simplification—literally. While competitors build orchestration frameworks with task queues, agent hierarchies, and complex state machines, Anthropic shipped a CLI that writes 90% of its own code using the simplest possible control flow.
This isn’t dumbing down the problem. It’s a philosophical stance on what AI agent architecture should be: trust the model, don’t over-engineer around limitations, and recognize that simplicity scales better than complexity.
The Philosophy: Simple is Better Than Complex
When I first examined Claude Code’s architecture, I expected layers of abstractions. What I found was closer to a Unix pipeline than a microservices mesh. The core execution loop looks approximately like this:
while not task_complete:
user_input = get_input()
model_response = call_claude(user_input, context)
results = execute_tools(model_response.tool_calls)
context.append(results)Four lines. One loop. That’s it.
This violates everything we’ve learned about “proper” AI agent architecture. Where’s the planning layer? The reflection mechanism? The multi-agent coordination? The sophisticated memory management?
The answer: trust the model to handle it.
Counter to Industry Trends
Compare this to what the industry has been building. OpenAI’s Codex-based systems layer complexity on complexity:
- Orchestration frameworks that route tasks between specialized agents
- Planning modules that decompose problems into dependency graphs
- Verification layers that check code before execution
- State machines that manage agent lifecycles
- Message queues that coordinate async operations
All of this infrastructure exists because the underlying assumption is: the model isn’t smart enough, so we need systems to compensate.
Claude Code takes the opposite bet: Claude Sonnet 4.5 is smart enough. Give it tools, give it context, and get out of the way.
Bash as Universal Adapter
The most elegant decision in Claude Code isn’t what it includes—it’s what it excludes. Instead of implementing 100 specialized tools (read_file, write_file, list_directory, search_code, run_tests, git_commit, etc.), Claude Code provides one flexible tool: Bash.
// Not this:
const tools = [
readFileTool,
writeFileTool,
searchFileTool,
gitTool,
npmTool,
dockerTool,
// ... 94 more tools
];
// This:
const tools = [bashTool];Why does this work? Because Bash is already a universal adapter. Every operation you need—file manipulation, process management, network requests, version control—already has a battle-tested CLI tool. Claude learns to compose these tools instead of learning bespoke APIs.
The benefits compound:
- Zero maintenance burden - Bash tools evolve independently, Claude Code inherits improvements for free
- Infinite extensibility - Any CLI tool is immediately available without framework changes
- Familiar mental model - Developers already know these tools, so agent behavior is predictable
- Cross-platform compatibility - Standard Unix tools work everywhere
- Composability - Tools chain naturally (
grep | sed | awkvs implementing search + transform + extract separately)
When you give Claude Code a task like “find all TypeScript files importing React and count their lines,” it doesn’t need a specialized code analysis tool. It just runs:
find . -name "*.ts" -exec grep -l "import.*React" {} \; | xargs wc -lThis is the Unix philosophy applied to AI agents: do one thing well (Bash execution), and compose to handle complexity.
Context Management Philosophy
Here’s where Claude Code diverges most dramatically from competitors: context strategy.
Most AI agent frameworks obsess over preserving every detail. They build elaborate memory systems—short-term, long-term, episodic, semantic. They implement retrieval mechanisms that surface relevant past interactions. They maintain persistent knowledge graphs.
Claude Code’s philosophy: The longer the context, the stupider the agent.
This sounds counterintuitive. Don’t agents get smarter with more information? Yes, to a point. Then they get confused. They overthink. They chase irrelevant patterns. They hallucinate connections that don’t exist.
Claude Code aggressively prunes context. Each interaction gets a clean slate with minimal carry-forward. Only essential state survives between turns:
- Current working directory
- Recent file contents (only what’s been read)
- Last few commands and their outputs
- Explicit user instructions
That’s it. No elaborate memory systems. No sophisticated retrieval. Just enough context to maintain continuity, then reset.
The result: Claude Code stays focused. It doesn’t get lost in its own history. It doesn’t over-optimize for edge cases from three days ago. It solves the current problem with fresh eyes.
Trust the Model, Don’t Engineer Around It
This philosophy shows up everywhere in Claude Code’s design decisions:
No Planning Layer
Competitors implement explicit planning phases. The agent must first decompose the task, build a dependency graph, identify risks, then execute.
Claude Code: just start. The model is smart enough to plan implicitly while working. If it needs to think through architecture, it will. If the task is obvious, it won’t waste time.
No Verification Layer
Many frameworks require code to pass through verification before execution. Static analysis checks. Security audits. Confirmation prompts.
Claude Code: execute and observe. If something breaks, the model sees the error and fixes it. This turns out to be faster than trying to verify everything upfront. The model learns from failures more effectively than from pre-execution checks.
No Multi-Agent Coordination
Current AI agent research focuses heavily on multi-agent systems. Specialized agents for different domains, communicating through protocols, voting on decisions.
Claude Code: one agent, one model. Specialization happens through tool selection and context framing, not agent proliferation. One coherent intelligence working on the problem beats a committee of narrow specialists.
No State Machines
Frameworks like LangChain implement elaborate state machines to manage agent lifecycles: initialize → plan → execute → reflect → update.
Claude Code: the while loop is the state machine. The model decides when to gather information, when to take action, when to verify, when to complete. State transitions happen naturally in the conversation flow, not through enforced checkpoints.
The 90% Self-Written Stat
Perhaps the most remarkable aspect: Claude Code wrote 90% of its own implementation. This isn’t marketing spin—it’s a natural consequence of the architecture.
When your system is simple enough that the AI can understand it, the AI can extend it. The development loop becomes:
- Human: “We need a feature to handle X”
- Claude: reads codebase, understands architecture, implements feature
- Human: reviews, merges
This works because Claude Code’s architecture has minimal abstraction layers. There’s no framework-specific DSL to learn. No elaborate object hierarchies to navigate. Just straightforward TypeScript implementing a simple control loop.
The implications are profound. As Claude models improve, Claude Code improves—not through manual development, but through self-modification. The tool evolves with the model that powers it.
Comparison: OpenAI Codex Architecture
Let’s contrast with OpenAI’s approach. Codex-based systems (like GitHub Copilot’s agent features) typically implement:
class CodexAgent:
def __init__(self):
self.planner = TaskPlanner()
self.executor = CodeExecutor()
self.verifier = CodeVerifier()
self.memory = MemoryManager()
self.coordinator = AgentCoordinator()
async def handle_task(self, task):
# Phase 1: Planning
plan = await self.planner.decompose(task)
# Phase 2: Validation
validated_plan = await self.verifier.check_plan(plan)
# Phase 3: Execution
for step in validated_plan.steps:
# Check memory for similar past tasks
similar = await self.memory.retrieve_similar(step)
# Execute with coordination
result = await self.coordinator.execute_with_agents(
step,
context=similar
)
# Verify result
if not await self.verifier.check_result(result):
await self.handle_failure(step, result)
# Update memory
await self.memory.store(step, result)
# Phase 4: Reflection
await self.memory.reflect_on_task(task, results)Compare this to Claude Code:
class ClaudeCode:
async def handle_task(self, task):
context = [task]
while not self.is_complete(context):
response = await claude.messages.create(
messages=context,
tools=[bash_tool, read_tool, write_tool]
)
if response.tool_calls:
results = await self.execute_tools(response.tool_calls)
context.append(results)
context.append(response)The Codex approach assumes the model needs extensive scaffolding. The Claude approach assumes the model is the scaffolding.
When Simplicity Fails
To be fair, this architectural philosophy has limitations:
Long-Running Tasks
For tasks spanning hours or days, Claude Code’s stateless approach struggles. There’s no checkpoint system, no resume mechanism. If execution fails midway through a 100-step migration, you start over.
Complex frameworks win here with their state persistence and recovery mechanisms.
Multi-Domain Expertise
When a task requires specialized knowledge from multiple domains (legal + technical + financial), a single generalist agent may underperform compared to a team of specialized agents.
The multi-agent frameworks have an advantage for truly cross-functional work.
Audit Requirements
In regulated industries, you need detailed logs of decision-making. Why did the agent choose option A over B? What information informed this choice?
Claude Code’s implicit reasoning is harder to audit than frameworks with explicit planning phases that log decision rationale.
Resource Optimization
When running hundreds of agents in parallel, sophisticated orchestration frameworks can optimize resource allocation, queue management, and load balancing.
Claude Code’s simple loop doesn’t optimize for multi-tenancy or resource efficiency at scale.
Why It Works Anyway
Despite these limitations, Claude Code’s architecture succeeds because it optimizes for the common case:
- Most tasks are short-lived (minutes to hours, not days)
- Most tasks are single-domain (write code, debug issue, refactor module)
- Most developers prefer transparency over auditability
- Most use cases are single-user (developer with their CLI)
For this 80% use case, the simple architecture outperforms complex alternatives. It’s faster to build, easier to understand, simpler to debug, and more reliable in production.
And when you do need the complex features, you can always layer them on top. The simple foundation supports extension better than a complex foundation supports simplification.
Architectural Principles
What can we extract as general principles from Claude Code’s design?
1. Prefer Implicit Over Explicit
Let the model handle planning, verification, and coordination implicitly rather than building explicit systems for each. Trust model intelligence over framework intelligence.
2. Minimize Abstraction Layers
Every abstraction layer between the model and the task adds latency, complexity, and failure modes. Keep the path short.
3. Use Existing Tools
Don’t build bespoke AI agent tools. Integrate existing CLI tools that are already robust, well-documented, and familiar to users.
4. Context is a Budget, Not a Resource
More context isn’t always better. Be aggressive about pruning irrelevant information to keep the model focused.
5. Fail Fast and Observe
Rather than preventing failures through elaborate verification, let failures happen quickly, observe them, and recover. The model learns more from errors than from prevention.
6. One Loop, Not Many States
Complex state machines create cognitive overhead for both developers and models. A simple loop with implicit state transitions is easier to reason about.
Practical Takeaways
If you’re building AI agent systems, consider:
Start Simple: Implement the minimal viable control loop first. Add complexity only when you hit actual limitations, not anticipated ones.
Trust Your Model: If you’re using frontier models (GPT-4, Claude 3.5+, Gemini Ultra), they’re smarter than your orchestration framework. Give them good tools and get out of the way.
Prune Aggressively: More context usually means worse performance. Keep only what’s immediately relevant.
Use Bash: Seriously. Before implementing a specialized tool, check if a Bash command would work. You’ll be surprised how often it does.
Measure Simplicity: Track the lines of code in your agent framework. If it’s growing faster than capabilities, something’s wrong.
Let the AI Maintain Itself: If your architecture is simple enough, the AI should be able to extend and modify it. This is a forcing function for clarity.
The Philosophy Wins
Claude Code’s architecture isn’t about cutting corners or shipping an MVP. It’s a deliberate philosophical stance: simple systems scale better than complex ones when powered by sufficiently capable models.
This inverts the traditional engineering wisdom. We’re used to building systems that compensate for weak components. When you have weak CPUs, you build elaborate caching layers. When you have unreliable networks, you build sophisticated retry mechanisms. When you have buggy code, you build comprehensive test suites.
But what do you do when the component is extremely capable? When the model can plan, verify, and coordinate on its own?
You get out of the way. You provide the minimal interface—tools, context, and a control loop. Then you trust.
That’s the bet Claude Code makes. Based on the results—a tool that developers actually use, that maintains itself, that handles real-world complexity—it’s a bet that paid off.
The four-line architecture beat the complex frameworks not by matching their features, but by recognizing most of those features aren’t necessary when you trust the model to be smart.
Sometimes the most sophisticated thing you can build is something simple.
Jon Roosevelt is an AI architect and healthcare technology executive. He builds production AI systems at scale and thinks deeply about what makes software maintainable, reliable, and actually useful. This analysis is based on examining Claude Code’s behavior, architecture patterns, and public documentation—not insider information.