Field-Level Ensemble OCR: Getting 74.8% Accuracy from Two Mediocre Vision Models
I've been running OCR on insurance cards at our urgent care clinics for a few months now. Patients hand over their card at check-in, staff snaps a photo, and our system extracts member IDs, group numb
I’ve been running OCR on insurance cards at our urgent care clinics for a few months now. Patients hand over their card at check-in, staff snaps a photo, and our system extracts member IDs, group numbers, payer names, and pharmacy details automatically. It works. Mostly.
The problem is “mostly.” Our single-model approach — minicpm-v:8b running through a self-hosted CardOCR API — was hitting about 56% exact match accuracy across 10 key fields on a 27-card test set. That means nearly half the fields needed manual correction. Staff were spending almost as much time fixing OCR output as they would have spent typing it manually.
The Insight: Different Models Fail Differently
I ran a systematic comparison of two open-source vision models against our ground truth dataset:
- minicpm-v:8b — A compact multimodal model, great at structured fields
- llama3.2-vision:11b — Meta’s larger vision model, better at reading descriptive text
The field-level breakdown told the real story:
| Field | minicpm-v:8b | llama3.2-vision:11b | Best Model |
|---|---|---|---|
| member_id | 74.1% | 66.7% | minicpm-v |
| group_number | 63.0% | 51.9% | minicpm-v |
| subscriber_name | 81.5% | 77.8% | minicpm-v |
| payer_id | 11.1% | 7.4% | minicpm-v |
| plan_name | 29.6% | 22.2% | minicpm-v |
| copay | 59.3% | 48.1% | minicpm-v |
| payer_name | 51.9% | 59.3% | llama3.2-vision |
| rx_bin | 70.4% | 74.1% | llama3.2-vision |
| rx_pcn | 48.1% | 59.3% | llama3.2-vision |
| rx_grp | 70.4% | 77.8% | llama3.2-vision |
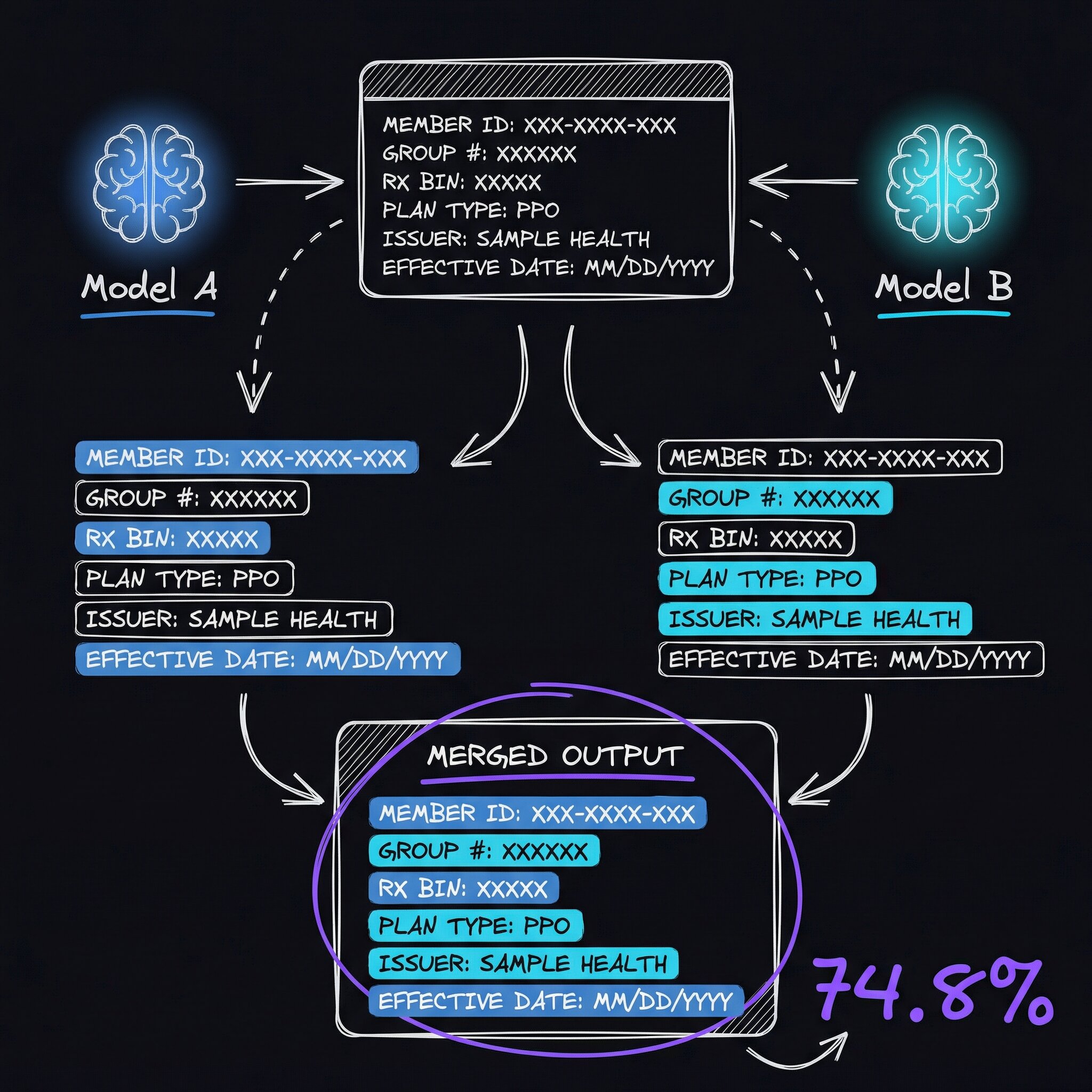
minicpm-v dominates on structured ID fields — member IDs, group numbers, names. llama3.2-vision wins on pharmacy fields (RxBIN, RxPCN, RxGrp) and payer names. Neither model is great at everything, but together they cover each other’s blind spots.
The Ensemble Approach
Instead of picking one model, we route each field to whichever model is best at extracting it:
Insurance Card Image
│
├──→ CardOCR (minicpm-v:8b) ──→ member_id, group_number,
│ subscriber_name, payer_id,
│ plan_name, copay
│
└──→ Ollama (llama3.2-vision) ──→ payer_name, rx_bin,
rx_pcn, rx_grp
│
└──→ Merge by field routing tableBoth models run in parallel — we’re already waiting 3-5 seconds for a single model, so running two concurrently costs almost nothing extra (max of the two, roughly 5-6 seconds total).
Results
The ensemble improved accuracy meaningfully:
| Metric | Single Model | Ensemble | Improvement |
|---|---|---|---|
| Exact match | 55.9% | 59.3% | +3.4 points |
| Fuzzy match | 72.9% | 74.8% | +1.9 points |
A 3.4-point improvement in exact match means fewer fields for staff to correct per card. On a busy day with 50+ patient check-ins, that adds up.
Production Integration
The implementation keeps things simple. The OCR service calls both models in parallel using a thread pool, then merges results using the routing table:
# Both models run concurrently
with ThreadPoolExecutor(max_workers=2) as executor:
cardocr_future = executor.submit(call_cardocr, image)
ollama_future = executor.submit(call_ollama, image)Key design decisions:
-
Graceful degradation — If Ollama fails, fall back to CardOCR-only results. If CardOCR fails but Ollama succeeds, use what we have. The system never returns worse results than before.
-
Feature flag —
OCR_ENSEMBLE_ENABLED=truetoggles the ensemble on or off. Set to false and behavior is identical to the original single-model path. -
JSON repair — LLMs don’t always return clean JSON. The Ollama integration includes a repair layer that handles markdown code blocks, truncated output, mismatched braces, and falls back to regex extraction as a last resort.
-
No caller changes — All five integration points (patient registration, admin EHR, re-run endpoint, etc.) call the same
extract_insurance_card()method. The ensemble is entirely internal.
What I Learned
You don’t need a better model — you need the right model for each field. Two 8-11B parameter models running on a single GPU, each mediocre on their own, outperform either one alone when you route fields intelligently. This is a general pattern worth remembering: before upgrading to a bigger model, check if your current models have complementary strengths.
Field-level evaluation matters more than aggregate scores. If I’d only looked at overall accuracy, I would have picked minicpm-v (56% vs 53% overall) and missed that llama3.2-vision was significantly better on 4 out of 10 fields.
Parallel execution makes ensembles cheap. The latency cost of running two models is not 2x — it’s max(model_a, model_b) when you parallelize. For an insurance card upload that already takes a few seconds, the user doesn’t notice.
The system is live now at our clinics. Next step is expanding the test set and seeing if a third model (or a fine-tuned one) can push accuracy past 80%.