Agentic Engineering, Part 3: Tracing Every Code Path Before It Becomes a Bug
BugBot finds bugs in code that's already written. But what about the bugs that exist because the architecture is wrong — where the code does exactly what it says, but "what it says" is inconsistent ac
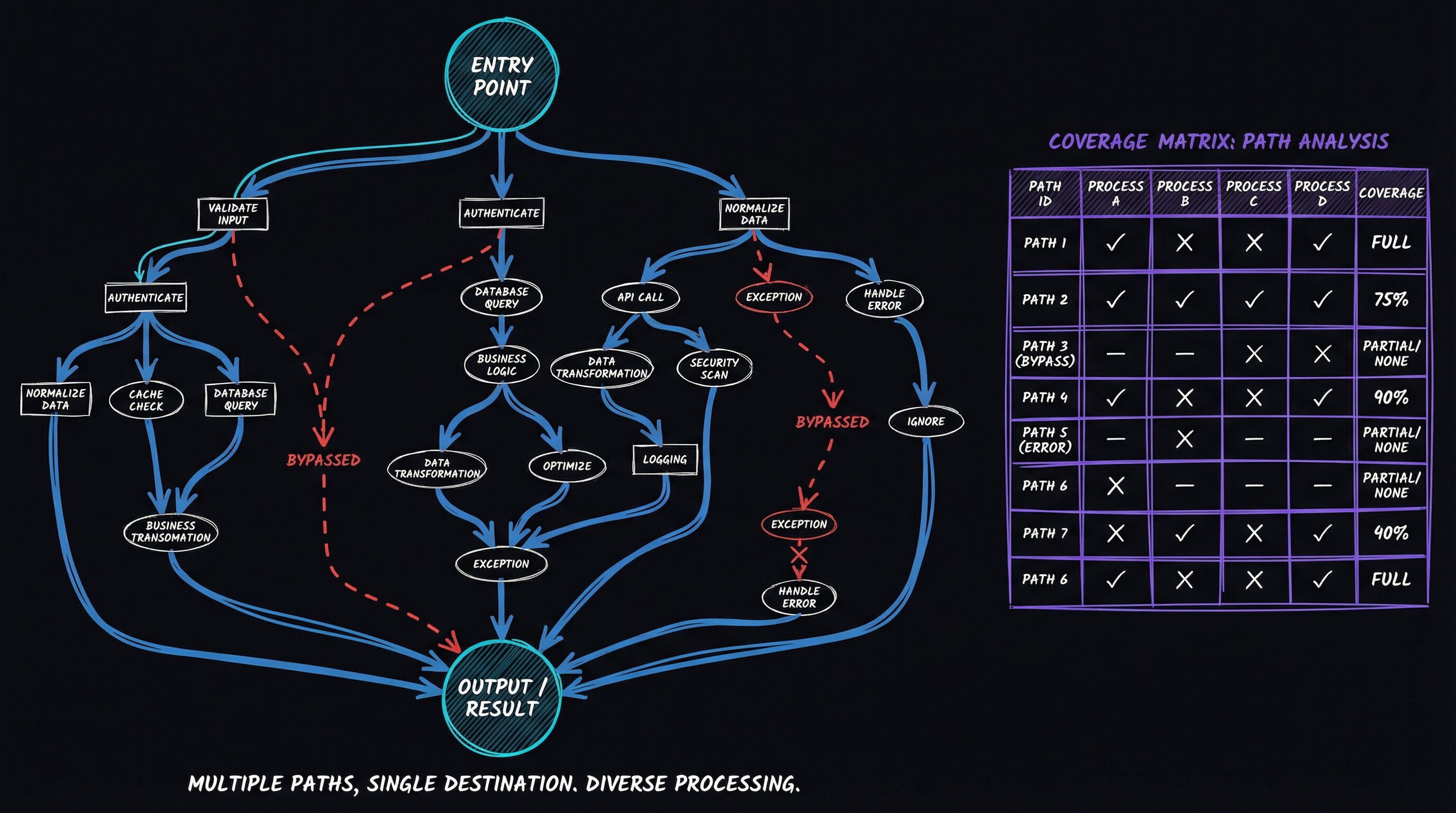
BugBot finds bugs in code that’s already written. But what about the bugs that exist because the architecture is wrong — where the code does exactly what it says, but “what it says” is inconsistent across six different call sites that each implement their own version of the same logic?
I discovered this the hard way. A feature for visit-reason notes was originally added to book_appointment(). It worked perfectly there. What I missed: four other functions also call create_appointment() and none of them created the note. The bug wasn’t in the code — it was in the architecture. The side effect lived in the wrong layer.
That pattern — duplicated logic, bypassed pipelines, side effects in the wrong place — keeps showing up in any codebase that grows fast. So I built ArchReview, a skill that traces every code path through a feature and maps where paths diverge.
Two Modes: Audit and Design
ArchReview has two workflows that form a pipeline:
| Workflow | What It Does | When To Use |
|---|---|---|
| AuditFeature | Trace all code paths, map entry points, find structural problems | ”Why is this broken?” or “How does this actually work?” |
| DesignSolution | Research patterns, run a Red Team debate, generate implementation spec | ”How should we fix this?” |
You can run them independently or chain them: audit first to understand the architecture, then design a solution for the problems found.
How AuditFeature Works
When invoked, AuditFeature spawns five specialized agents in parallel. Each agent has a narrow focus and deep expertise:
| Agent | Focus | Output |
|---|---|---|
| Entry Point Mapper | Find EVERY call site for the key function, trace what happens before and after each call | Numbered list of all entry points with data flow |
| Logic Duplication Detector | Find ALL copies of the feature’s core logic, diff them against each other | Coverage matrix showing which filters/transforms each path applies |
| Data Flow Tracer | Follow data from source to sink, find monkey-patches and overrides | Execution order map with every transformation point |
| Transaction Safety Auditor | Verify every database write uses BEGIN IMMEDIATE transactions | Safety matrix: N of M write paths are transaction-safe |
| i18n Completeness Checker | Verify every data-i18n key exists in all language dictionaries | Translation coverage: N of M keys are fully translated |
The key output is the coverage matrix — a table showing which processing steps each code path applies:
| Code Path | Filter A | Filter B | Post-hook | SSE Broadcast |
|------------------|----------|----------|-----------|---------------|
| SSE update | Yes | NO | NO | N/A |
| UI click | Yes | Yes | Yes | Yes |
| API call | Yes | Yes | NO | Yes |
| Timer refresh | NO | NO | NO | NO |When you see a matrix like that, the architecture problem is obvious: four paths to the same destination, each applying a different subset of processing. The bugs aren’t in any individual path — they’re in the gaps between paths.
Template Variable Completeness
One of ArchReview’s most valuable checks is something no linter catches: template variable completeness across render_template callers.
In Flask, multiple routes can render the same template. If you add a new feature to one route, every other route that renders that template needs to pass the same variables. Miss one and you get a NameError in production — but only on the route you didn’t test.
The Entry Point Mapper agent greps for every render_template call for each template, compares the keyword arguments, and flags any variable present in some callers but missing from others. This caught a real bug: both /welcome and /flow render kiosk/welcome.html, but only /flow passed the lunch_break variable. The lunch break banner worked on one route and crashed the other.
Transaction Safety Auditing
This one is specific to SQLite but the pattern generalizes. Python’s sqlite3 module uses DEFERRED transactions by default — it acquires a shared lock on first read, then tries to upgrade to exclusive on write. Under concurrent load (Gunicorn workers), this upgrade fails instantly, completely bypassing busy_timeout. The fix is BEGIN IMMEDIATE, which acquires a write lock upfront.
ArchReview’s Transaction Safety agent traces every database write in the feature under audit and verifies it goes through the transaction() context manager (which issues BEGIN IMMEDIATE). It produces a table:
| Write Location | Service | Uses transaction()? | Risk |
|-------------------------|-------------------|---------------------|----------------------------|
| data_service.py:89 | DataService | Yes | None |
| app_db.py:340 | AppDatabase | No — bare commit() | P0: concurrent lock failure |This is architectural, not syntactic. A linter can’t tell you that bare commit() is dangerous specifically because of how SQLite handles lock upgrades under concurrency. The agent understands the architectural context because the workflow explains it.
DesignSolution: Red Team Debates
Once AuditFeature maps the problems, DesignSolution finds the fix. It starts with parallel research — two agents search for patterns in open-source codebases solving similar problems, one in the primary domain and one in adjacent domains (React patterns applied to vanilla JS, backend pipeline patterns applied to frontend, etc.).
From the research, I select the two most promising approaches. Then a Red Team agent debates them:
For EACH approach:
1. Steel-man it (present it at its strongest)
2. Identify the top 3 risks/weaknesses
3. Score on: complexity, regression risk, cognitive load,
edge case handling, future extensibility
4. Deliver a verdict with what the winner should borrow
from the loserThe structured debate consistently produces better architectural decisions than “which approach should I use?” The steel-manning forces honest evaluation of each option; the scoring matrix prevents gut-feel decisions.
The output is a full implementation spec written to .agent/specs/ — problem statement, before/after architecture, every call site that needs migration, and a testing checklist.
The Difference From CodeReview
I have three review skills, and people ask how they’re different:
| Skill | Scope | Depth | Output |
|---|---|---|---|
/PortalCodeReview | Broad codebase sweep | Surface — pattern matching across 12 categories | Prioritized findings list |
/PortalBugBot | Recent changes | Deep — adversarial loop with attack angles | Fixed bugs + regression tests |
/PortalArchReview | Single feature | Deepest — full code path trace | Architecture audit + implementation spec |
CodeReview is a net cast wide. BugBot is a drill aimed at recent changes. ArchReview is an X-ray of one system’s skeleton. They complement each other because they find different classes of problems: CodeReview finds anti-patterns, BugBot finds bugs, ArchReview finds architectural debt.
Composing Into the Pipeline
In practice, these skills layer:
- Build a feature on a branch
/PortalArchReviewif the feature touches complex pipelines — audit before implementation to understand the architecture you’re modifying/PortalBugBotafter implementation — adversarial review of your changes/PortalCodeReviewperiodically — broad sweep for accumulating anti-patterns/PortalDevFlowthroughout — enforces the pipeline at every step
Each skill encodes knowledge I’ve accumulated through bugs that shipped. The visit-reason note bug became a rule in ArchReview. The phone normalization bug became an attack angle in BugBot. The timezone bugs became a category in CodeReview. The skills get smarter because the mistakes are encoded as structure, not just memory.
What I Learned
Architecture audits before implementation save more time than reviews after. When I run ArchReview on a feature before modifying it, I find the five call sites that all need updating instead of finding them one at a time through production bugs.
Structured debate beats intuition for architectural decisions. The Red Team workflow has reversed my initial instinct on approach selection multiple times. Steel-manning the option I was leaning against often reveals it’s actually better.
The coverage matrix is the most valuable artifact. A single table showing which processing steps each code path applies makes invisible inconsistencies visible instantly. Most architectural bugs are gaps in that matrix.
Next: Part 4 covers how all nine skills compose into a complete development lifecycle — from cleaning test data to deploying to production.